
Introduction
Founded in 1997, Scribendi Inc. is an ISO 9001:2015-certified online editing and proofreading company. With artificial intelligence (AI) reshaping our lives, both on- and offline, Scribendi is developing new technological applications for its editing and proofreading services.
Scribendi AI, an AI-driven grammatical error correction (GEC) tool that the company’s editors use to improve consistency and quality in their edited documents. Scribendi AI does this by identifying errors in grammar, orthography, syntax, and punctuation before editors even touch their keyboards, leaving them with more time to focus on crucial tasks, such as clarifying an author’s meaning and strengthening his or her writing overall.
Currently, many GEC tools are available, but few leverage deep learning algorithms. After the Deadline [1], for example, uses n-gram-based statistical language modeling, and LanguageTool [2] uses a rule-based approach combined with statistical machine learning. This paucity of deep-learning algorithms among GEC tools has been due to the lack of reliable annotated datasets for training [3]. Scribendi Inc., however, has a dataset of approximately 30-million sentences from its various online editing and proofreading services (about 15 times the number of sentences available in the largest public datasets [4]). Thus, Scribendi AI has sufficient data for training as a deep-learning algorithm and is ready for testing.
Having an effective methodology to evaluate GEC tools is essential, but three major challenges have emerged. First, many current evaluation metrics, such as precision/recall [5][6] and the M2 score [7], compare edited text with a single gold-standard correction, word for word [8]. Thus, they do not take into account the dynamics of the English language—grammatical errors in sentences can often be corrected in multiple ways, meaning that metrics sometimes evaluate changes as incorrect, even when they are not, strictly speaking, wrong [8][9]. Second, the datasets available for GEC research involve errors that are usually limited to certain simple types. Thus, using these datasets to train or test GEC tools is ineffective because the data do not represent the complexities of documents written by humans. This limitation diminishes the tools’ ability to provide substantial, meaningful corrections, and it diminishes the metrics’ ability to test how well these tools perform with actual documents. Third, the datasets available for GEC research comprise isolated sentences. The lack of contextual knowledge about how any one isolated sentence relates to another in a line of human reasoning or in terms of a specific writing convention further diminishes the metrics’ ability to test how well GEC tools perform with actual documents.
In response to these challenges, we have developed a methodology to improve testing accuracy when evaluating GEC tools, and we have provided a better, contextually rich dataset to test the tools’ performance. We implemented this methodology in a comparative analysis, testing three different versions of Scribendi AI against the GEC tools of three leading competitors in the editing and proofreading field. In all testing phases, a version of Scribendi AI outperformed the three competitors.
The next section of this paper outlines our methodology and the testing procedures. The section after that presents the test results, followed by a section detailing our conclusions.
Materials and Methods
Our methodology does not require the development of a single gold standard when testing GEC tools. Instead, we began by assessing the raw data in terms of various edits that could be correct. For the tests conducted in this study, we relied on the expertise of Scribendi’s editors to annotate the errors with categorizations based on the authoritative Chicago Manual of Style (CMOS, 17th edition) [12].
In preparation for the first test, we applied our methodology to 20 selected sentences in the public National University of Singapore Corpus of Learner English (NUCLE) dataset (see Appendix A for the 20 selected sentences) [13]. To demonstrate the application of our methodology, we present the following example (Sentence 1) from the dataset:
Bigger farming are use more chemical product and substance to feed fish.
A concise edit for this sentence would be the following:
Big farms use more chemicals to feed fish.
However, because this sentence is taken out of context, numerous variations are equally (perhaps even more) accurate. If the context previously established a comparative relationship between bigger and smaller farms, an example of such could be the following:
Bigger farms use more chemicals to feed fish.
If the context previously emphasized products composed of chemicals (rather than the chemicals themselves), the revision could read as follows:
Bigger farms use more chemical products to feed fish.
If the context previously distinguished between the chemical composition of a “product” and a “substance,” the revised sentence could be the following:
Bigger farms use more chemical products and substances to feed fish.
From a different line of thinking, if the word “are” in the sample is not an extraneous auxiliary verb but rather a typo of “areas,” the sentence could be the following:
Bigger farming areas use more chemical products and substances to feed fish.
Likewise, the author may have wished to express an ongoing action, in which case the sentence could be the following:
Bigger farms are using more chemical products and substances to feed fish.
We could go on. The point is that our corrections to the raw data are not absolute because a change to one word in a sentence could correct another ostensibly erroneous word elsewhere in the sentence. Figure 1 presents the corpus of errors for the raw data discussed in this paragraph.
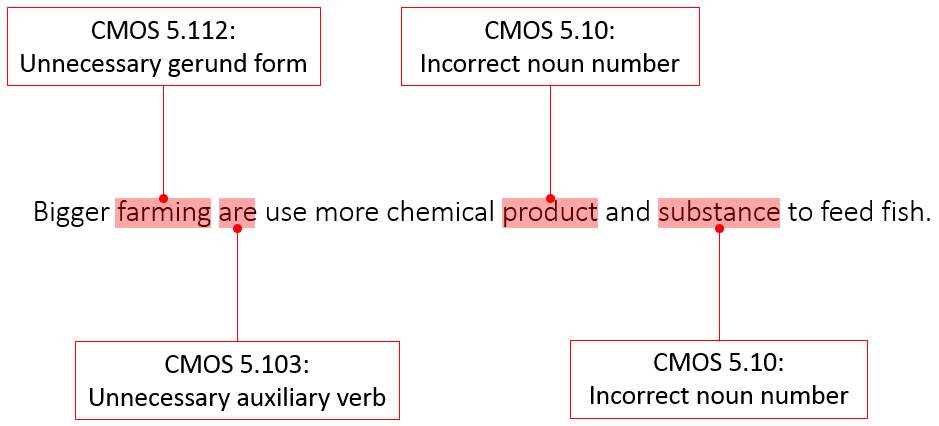
Figure 1. Sentence 1 from the public NUCLE dataset, with annotations based on CMOS.
Having annotated the 20 sample sentences for all errors, we subsequently used the three versions of Scribendi AI and three competitors’ GEC tools to edit the 20 sentences. Scribendi’s editors then used their expertise to determine whether a change in the edited sentences led to a direct or indirect correction of the raw data. Figure 2 shows the six edited versions of the sentence shown in Figure 1.

Figure 2. Edited versions of Sentence 1 (public NUCLE dataset) using the six tested GEC tools.
In each case, the GEC tools incorrectly (relative to the rest of the edited sentence) retained “farming” as the subject and, in principle, retained the comparative condition of “Bigger” in the original sentence. However, Competitor 1 introduced a vocabulary error based on the assumption that size and prominence are synonymous. Another crucial difference was verb conjugation in relation to the object of the sentence. Competitor 2 changed the tense of the principal verb from the present to the past tense, presumably to retain the auxiliary verb “are” (which does not agree with the singular subject, “farming”); the second version of Scribendi AI correctly matched the singular “farming” with the singular auxiliary verb “is” but erroneously changed the principal verb from the present to the past tense. In both cases, the phrase “more chemical product or substance” does not grammatically follow the edited verb conjugation. Finally, the challenge of distinguishing between count and mass nouns was a stumbling block for Scribendi’s competitors. Competitors 1 and 2 both left “product” and “substance” in the mass singular form, whereas Competitor 3 changed “product” to “products” but left “substance” in the singular. Thus, the first and third versions of Scribendi AI provided the most accurate edits to this sentence.
This first sample sentence is rather simple, as are many of the sentences in the public NUCLE dataset. Even the more complex samples from this dataset typically provide discrete errors in sentences that are often easy to understand. This does not accurately reflect the writing quality of documents that Scribendi’s editors frequently encounter, especially when the majority of Scribendi clients are people for whom English is a second language (ESL). Therefore, we conducted further tests to evaluate the various GEC tools against more complicated sentences organized in paragraphs. Specifically, we selected four paragraphs (19 sentences in total) from four mock assignments that Scribendi Inc. uses to test prospective editors (see Appendix B for the four selected paragraphs). The paragraphs in these mock assignments more accurately reflect the writing quality of documents that Scribendi Inc. encounters in an English-language context with predominantly ESL writers.
As we had done with the public NUCLE dataset, here we applied our methodology to assess errors among the 19 sentences in paragraphs from the mock assignments. Sentence 16 from this dataset serves as an example:
Then the bats were separated into two groups; 1 Group hibernate 2 and the control group.
Here, the independent clause is clear, but the author does not understand how to establish or organize a run-in list. An accurate version of the sentence would be the following:
Then, the bats were separated into two groups: (1) the hibernation group and (2) the control group.
Figure 3 shows the various errors in this sentence, based on annotations using CMOS.
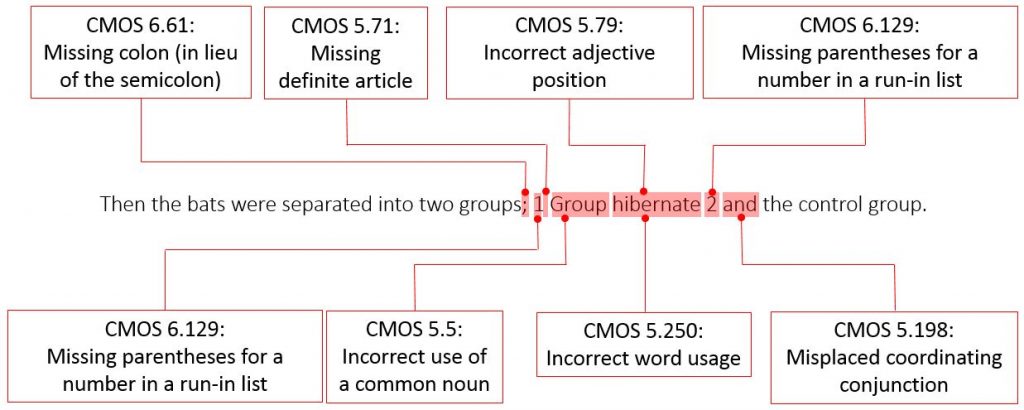
We then used the three versions of Scribendi AI and three competitors’ GEC tools to correct the dataset from the Scribendi Inc. mock assignments. Figure 4 contains the edits of Sentence 16, courtesy of the six tested GEC tools.

Figure 4. Edited versions of Sentence 16 (Scribendi Inc. mock assignments dataset) using the six tested GEC tools.
Only two of the tested GEC tools provided a change to the independent clause in Sentence 16. Competitor 2 erroneously changed “bats” to “boats” (boats do not hibernate), while the third version of the Scribendi AI improved the sentence, adding a comma to set off “Then,” the introductory adverb. Only the first and third versions of Scribendi AI recognized the need to establish a run-in list, changing the semicolon to a colon. Further, only the third version of Scribendi AI and Competitor 3’s GEC tool properly corrected the capitalization of “Group.” However, Competitor 3’s tool also incorrectly spelled out “one” and erroneously added the preposition “for” before the retained numeral “2.” Therefore, because all the tested GEC tools failed to correct the other aspects of this run-in list, the third version of Scribendi AI provided the most correct version of this sentence.
Finally, because the Scribendi Inc. mock assignments dataset involves full paragraphs, the performance of the six tested GEC tools could be reevaluated in comparison with contextual knowledge. In other words, the previous test was based on 19 sentences, each in isolation. However, knowing the sentences that occur before or after any one sentence within a paragraph may result in a change in the types and amount of errors corrected. Take Sentence 4 of the Scribendi Inc. mock assignments dataset as an example:
School is very difficult, when I first landed on the stormy shores in the United States.
As a correctly revised and isolated sentence (all current GEC tools can only assess errors in isolated sentences), this might read as follows:
School was very difficult when I first landed on the stormy shores of the United States.
In other words, the verb tense of the independent clause changes from “is” to “was” to match the past event of having “first landed on the stormy shores of the United States.” However, the following is the same raw data in context with the sentence after it (Sentence 5):
School is very difficult, when I first landed on the stormy shores in the United States. I did not speak or read English, so you can imagine how difficult this certainly is, nevertheless I learnt it all so quickly!
In context, it is possible that the author’s “when” clause is not connected with the independent clause in Sentence 4 but rather with the first independent clause in Sentence 5:
School was very difficult. When I first landed on the stormy shores of the United States, I did not speak or read English, so you can imagine how difficult school certainly was; nevertheless, I learned it all so quickly!
None of the tested GEC tools could produce such a change, but an accurate edit of any paragraph could involve reorganizations across multiple sentences.
Results
Using our methodology to evaluate six GEC tools, we tabulated scores for edits to the public NUCLE dataset and to the Scribendi Inc. mock assignments dataset (the latter in terms of isolated sentences and paragraph-based context). Every error that a GEC tool failed to correct counted as one point against that tool’s performance. Furthermore, every time a GEC tool introduced an error that was not part of the original sentence (e.g., Competitor 1 changing “Bigger” to “More prominent” in Figure 2), it counted as one point against that tool’s performance. Finally, every time a GEC tool introduced an improvement to an original sentence, it was noted but not counted as part of the tool’s performance score (e.g., the third version of Scribendi AI adding a comma after “Then” in Figure 4). These improvements were not included as part of a tool’s performance score because they were not corrections to the sentences but rather better versions of the sentences. For example, adding a comma after an introductory adverb, such as “Then” in Sentence 16 of the Scribendi Inc. mock assignments dataset, is grammatically accurate, but the convention of omitting that comma is well established in current English usage. It was upheld herein that an improvement is not a correction.
Table 1 displays the performance scores of the six tested GEC tools when correcting the 20 selected sentences from the public NUCLE dataset. The number of “Errors identified” is the total number of potential errors minus the number of actual errors after all corrections were taken into account (e.g., Competitor 1: 80 – 41 = 39). The number of “Errors introduced” is the total number of errors that arose when a tested GEC tool made an incorrect change to a previously correct section of the sentence. This number was subtracted from the number of errors identified, thus resulting in a final score (e.g., Competitor 1: 39 – 6 = 33). That final score was then divided by the total number of errors in the raw data to determine accuracy as a percentage (e.g., Competitor 1: 33 / 80 = 41%). Consequently, of the six GEC tools tested with the public NUCLE dataset, the second version of Scribendi AI had the highest GEC percentage (50%). Competitor 3 had the most introduced errors (9), and the first version of Scribendi AI had the most improvements among the tested sentences (7).

Table 1. Results of the Six Tested GEC Tools Using the Public NUCLE Dataset
Table 2 displays the performance scores of the six tested GEC tools when correcting each of the 19 sentences in the Scribendi Inc. mock assignments dataset. The scoring system is identical to that shown in Table 1, and the third version of Scribendi AI had the highest GEC percentage (16%). Competitor 3, once again, had the most introduced errors (8), and the third version of Scribendi AI had the most improvements (3).

Table 2. Results of the Six Tested GEC Tools Using Isolated Sentences from the Scribendi Inc. Mock Assignments Dataset
Table 3 displays the performance scores of the six tested GEC tools using the same 19 sentences from the Scribendi Inc. mock assignments dataset, though now contextualized as four paragraphs. The scoring system is again identical to that shown in Table 1, and the third version of Scribendi AI again had the highest GEC percentage (13%). The number of introduced errors and improvements remained the same as the scores for the previous test.

Table 3. Results of the Six Tested GEC Tools Using Contextualized Sentences from the Scribendi Inc. Mock Assignments Dataset
In the final test, the GEC percentages for all six tested tools were lower than the scores for the previous test because these errors were based on contextual knowledge of each paragraph among the mock assignments. With this contextual knowledge, the number of errors increased from 64 possibilities (when treating each of the 19 sentences as discrete units) to 95 possibilities (when contextualizing the 19 sentences in terms of their four paragraphs). For example, several of the additional errors in this last evaluation were verb–tense disagreements that emerged when understanding the verb tenses of other sentences in the paragraph or when understanding the writing conventions in which the sentences occurred (e.g., the “Methods” section of a scientific paper). Thus, there were more opportunities in the final assessment for the GEC tools to miss errors, reducing the GEC percentages at a roughly comparable rate (between 1–4% for all six GEC tools).
Conclusions
In all three phases of testing, a version of Scribendi AI performed the best among the six GEC tools. With the public NUCLE dataset, the second version of Scribendi AI corrected 9% more errors than the nearest non-Scribendi competitor. With the Scribendi Inc. mock assignments dataset (evaluated in terms of isolated sentences), the third version of Scribendi AI corrected 3% more errors than the nearest non-Scribendi competitor. With the Scribendi Inc. mock assignments dataset (contextualizing the sentences in their paragraphs), the third version of Scribendi AI corrected 4% more errors than the nearest non-Scribendi competitor.
Although versions of Scribendi AI outperformed the competition in all three phases of testing, the tool’s optimal performance remains in the hands of a human editor. This is especially evident when comparing the results from all three phases. When confronted with error patterns that are common in difficult ESL writing (e.g., the samples from the Scribendi Inc. mock assignments dataset), a skilled editor would know which suggestions from Scribendi AI to accept and which to bypass in favor of the comprehension that, to date, the human brain alone can provide. Furthermore, while the tested GEC tools all analyzed text as a series of isolated sentences, an editor can usually see the whole paragraph (and, by extension, the whole document) to understand necessary agreements in terms of verb conjugation or the relationship between pronouns and their antecedents, to name just two examples of contextual knowledge.
We have published this article to stimulate discussion about methodologies for GEC tool evaluation. Our methodology is novel because it accommodates multiple correct edits to a single sentence rather than providing a single gold standard to which all variations are subjected. The logic of a gold standard cannot accurately be used to evaluate GEC tools because language is too dynamic. Nevertheless, the advantage of imposing a single gold standard is the potential to automate the evaluation process. Our methodology is limited because it relies on the judgment of human editors, and evaluations based on human judgment are time consuming and prone to error and bias. Thus, our methodology is novel, but it is not yet objective by any reasonable measure.
Future research could involve greater objectivity. We could submit blind versions of the GEC tools’ corrected sentences and paragraphs to multiple competitors in the editing and proofreading field, asking them to annotate the remaining errors based on CMOS. We could then compare the annotations and consequent scores among the GEC tools to assess statistical significance among the human components in the methodology. This would allow scores with statistically significant agreement among human evaluators to measure GEC percentages with even greater accuracy.
References
-
Mudge, Raphael. “The design of a proofreading software service.” Proceedings of the NAACL HLT 2010 Workshop on Computational Linguistics and Writing: Writing Processes and Authoring Aids. Association for Computational Linguistics (2010): 24–32.
-
LanguageTooler GmbH. LanguageTool: Proofreading Software.
-
Leacock, Claudia, Martin Chodorow, Michael Gamon, and Joel Tetreault. “Automated grammatical error detection for language learners.” Synthesis Lectures on Human Language Technologies 3.1 (2010): 1–134.
-
Junczys-Dowmunt, Marcin, Roman Grundkiewicz, Shubha Guha, and Kenneth Heafield. “Approaching neural grammatical error correction as a low-resource machine translation task.” Proceedings of NAACL-HLT. Association for Computational Linguistics (2018): 595–606.
-
Dale, Robert, and Adam Kilgarriff. “Helping our own: The HOO 2011 pilot shared task.” Proceedings of the 13th European Workshop on Natural Language Generation. Association for Computational Linguistics (2011): 242–249.
-
Dale, Robert, Ilya Anisimoff, and George Narroway. “HOO 2012: A report on the preposition and determiner error correction shared task.” Proceedings of the 7th Workshop on Building Educational Applications Using NLP. Association for Computational Linguistics (2012): 54–62.
-
Dahlmeier, Daniel, and Hwee Tou Ng. “Better evaluation for grammatical error correction.” Proceedings of the 2012 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics (2012): 568–572.
-
Felice, Mariano, and Ted Briscoe. “Towards a standard evaluation method for grammatical error detection and correction.” Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics (2015): 578–587.
-
Napoles C, Sakaguchi K, Post M, Tetreault J. GLEU without tuning. arXiv preprint arXiv:1605.02592. 2016 May 9.
-
Napoles C, Sakaguchi K, Post M, Tetreault J. Ground truth for grammatical error correction metrics. InProceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers) 2015 (Vol. 2, pp. 588-593).
-
Chollampatt, Shamil, and Hwee Tou Ng. “A reassessment of reference-based grammatical error correction metrics.” Proceedings of the 27th International Conference on Computational Linguistics. International Committee on Computational Linguistics (2018): 2730–2741.
-
University of Chicago. “About the Chicago Manual of Style.” Available at https://www.chicagomanualofstyle.org/help-tools/about
-
Dahlmeier, Daniel, Hwee Tou Ng, and Siew Mei Wu. “Building a large annotated corpus of learner English: The NUS Corpus of Learner English.” Proceedings of the 8th Workshop on Innovative Use of NLP for Building Educational Applications. Association of Computational Linguistics (2013): 22–31.
Appendix A
| Twenty Sentences from the Public NUCLE Dataset |
| 1 | Bigger farming are use more chemical product and substance to feed fish. |
| 2 | People tends to choose other medias, and that is why litterature is in danger. |
| 3 | I cast doubt that twenty years is too short time to prove the problem. |
| 4 | so the information technology and advanced technology are so much increased. |
| 5 | As the professor claimed the details and examples to strengthen the position of reading passage, which I, in the following pargarghs, would like to provide the evidence to present the whole views. |
| 6 | Firstly the striped bass consume large quantitiy of menhaden, secondly this fish is also a source of protein for farm animal, and fishing industry gives work some people in Virginia. |
| 7 | So it means there is no certain way about how migratintg birds find their way to the home. |
| 8 | Indeed, they threat lot of freshwater fish species because they need to eat and to find different kind of food in the oceans. |
| 9 | We still don’t know aliens to be or not to be in our solar system. |
| 10 | In my essy i want to focus on: how impotant is for students to learn facts. |
| 11 | Without the empirical experience, i think, the learner tend to forget all the information he or she have learned throuhout his or her learning process in a long term. |
| 12 | Therefore it is possible to believe that explosion of Tunguska was the explosion of asteroid. |
| 13 | Moreover before the oil and gas gone scientist will make new car that go by electricity or by sun light. |
| 14 | Ihad good life in my cauntry but everything I got from my patents. |
| 15 | Travelling in a group especially with a tour guide, helps us to make our trip be more productive. |
| 16 | To be sure, we Japanese take part in destroying enviroment because we consume most wood. |
| 17 | To be sure, we Japanese take part in destroying enviroment because we consume most wood. |
| 18 | Therefore french revolution happend in the middle age in Eruope because of that reasons. |
| 19 | They think what the celebrities say in the advertisement is true. |
| 20 | Anglo version of Christianity became popular in the northern Europe and still now many people are believing in its doctrines. |
Appendix B
| Nineteen Sentences (Four Paragraphs) from the Scribendi Inc. Mock Assignments Dataset |
| Paragraph | Sentence | |
| 1 | 1 | These fungi minute, are characterised in the young stages by gelatinous landscape. |
| 2 | There substance; bears considerable similitude to a sarcode, and never change from this—but as the species proceeded towards sophistication they lose their mucilaginous texture to a mass of spores intermixed with threads encircled from cellular peridium. | |
| 3 | In the genus Trichia, and we have in the seasoned specimen’s a somewhat globose peridium not grander than a mustard seed; and sometimes nearly of the same color. | |
| 2 | 4 | School is very difficult, when I first landed on the stormy shores in the United States. |
| 5 | I did not speak or read English, so you can imagine how difficult this certainly is, nevertheless I learnt it all so quickly! | |
| 6 | But over time I even made some friends who helped me so much. | |
| 7 | I learned that even though you do you’re a jerk, you’re American children are actually quite good good! | |
| 8 | Now I have so many friends here, I can not even imagine going back to Tokyo. | |
| 3 | 9 | As a scholar, I am very interested in computer science. |
| 10 | The game has always been my escape, I found myself excluded from the US members of the community. | |
| 11 | Since video games do not even need for us to speak any language, so they provide a way we connect to one and the other in interleaved mode. | |
| 12 | So I like the game so much, I even learned how to work and started doing my own. | |
| 13 | That’s why I want to study computer: bridging the gap between different people, and the establishment of the international community nerd. | |
| 4 | 14 | The authors used the thirteen largest bat-eared mouse, each adult male, but were arrested at different points in time and in different geographical locations, (kept in cage in darkness with light upside down with regular food and water along with dessert locusts only one time a week), Then the bats were trained to find food in a maze with three points and connected to a central fund large using a series of pipes, then the bat tube was chosen to enter, and which ended with a tray containing mealworms; the bats are rewarded only when they choose a particular feeding tube one; if he chooses the wrong feeding tube, and closed the holes they will get no reward. |
| 15 | This process continues until the bads choose the right tube up to a dozen times in the first ten trials of the course. | |
| 16 | Then the bats were separated into two groups; 1 Group hibernate 2 and the control group. | |
| 17 | Hibernate group hibernated forcibly for two month) with cold brain and control were prevented from hibernated. | |
| 18 | After a period or time of hibernation, all of said bads perform the same tests again. | |
| 19 | They find food in the maze and get those rewards but otherwise not and those holes close until they do it right 12 times in 10 times too. |
1 A generalized language evaluation understanding (GLEU) metric has been proposed [10] to evaluate GEC systems based on the grammaticality, fluency, and adequacy of output sentences, combined with human judgment. However, a recent study on reference-based GEC [11] claimed that the correlation of GLEU with human quality judgments is inconclusive due to the lack of appropriate significance tests and discrepancies in the methods and datasets used.
2 Crucially, Scribendi Inc.’s mock assignments (and the edited versions that prospective contractors submit to the company for evaluation) were not part of the training dataset for Scribendi AI. Therefore, the mock assignments could serve as material to test Scribendi AI among competing GEC tools.
3 Corrections using all six GEC tools in this study were tested against American English. Thus, “learnt” in British English, for example, becomes “learned.” This further demonstrates the importance of context because Sentence 7 in that paragraph uses “learned” instead of “learnt.” See Sentence 7 in Appendix B.
This tool is good for the people who have theory work, like content writers. I am experienced with this tool, I was installed it and i was really helpful. You blog introducing this tool, it’s great because this tool helps to improve the language.