
Written by: Ankit Vadehra and Pascal Poupart
1 Introduction
Grammar error correction (GEC) is an important and significant natural language processing (NLP) task. The objective of GEC is to correct grammatical errors and inconsistencies in a piece of text. Different models may focus on different spans of texts, ranging from sentences to whole documents. Models that can properly perform GEC can significantly benefit a large and diverse portion of the community.
GEC can be a diverse and varied problem. For instance, turning casual or informal writing, such as that found in chat or SMS messages, into formal sentences is a completely different task than trying to perform text improvement or editing on formal text spans (i.e., formal writing, research documents, grants etc.).
Depending on the problem, the type of data available to train an efficient model, as well as the properties of the data, may vary. Another challenge models face while trying to perform GEC is the fact that the original and improved sentences may be very similar, differing only by a small, single edit. Another significant issue for GEC is that a single sentence can be interpreted and corrected in multiple ways. These issues pose difficulties when training GEC systems. While testing a set of sentences, the GEC system may ignore certain edits in favor of improving their training objectives. Unnecessary or skipped edits can be an issue for a GEC system.
GEC may also incorporate the tangential task of grammar error detection (GED). GED predicts whether a sentence is correct. GEC can often encompass categorization for GED. The difference between the two tasks is that while GEC is evaluated on the generated correct sentence, GED is concerned with localizing and finding issues in the input text or evaluating the overall text. Sometimes, GEC systems can utilize the linguistic properties of the GED approach to perform corrections. We will discuss this hybrid model later on.
In this study, we compare top-performing GEC models and design and train new models to evaluate and compare the performance of GEC systems with the introduction of preliminary GED filtering. We hypothesize that strong grammar error detection classifiers can assist a GEC system and make the task of inference faster by using the GEC architecture only for sentences the GED model deems incorrect. We also introduce a new evaluation metric based on the number of useful edits a GEC system performs for an end user.
2 Approaches to Grammar Error Correction Models
In this work, we focused solely on GEC models that are trained and designed using neural networks or deep learning architecture, as they provide significant improvement and are considered to be state of the art with regard to their performance.
There are two popular and widely used model architecture approaches for GEC. The first makes use of the popular (and now standard) neural machine translation (NMT) architecture, which is built on the sequence-to-sequence (S2S) model. The second approach, sequence tagging, is based on an editing or tagging mechanism. It uses a tagged corrections technique in which the model first tries to identify inconsistencies and then provides corrections for a localized text span (i.e., word-level correction).
2.1 Sequence-to-Sequence Architecture
The neural network architecture for text-based input often makes use of models such as the recurrent neural network models GRU [CGCB14], LSTM [HS97], and Transformers [VSP+17].
The sequence-to-sequence (S2S) model is a deep learning architecture that can generate text based on a conditional input. The S2S model consists of encoder and decoder blocks. The encoder block is responsible for producing the sentence representation for the input sentence, which acts as the conditional text information used by the decoder block to generate the output text.
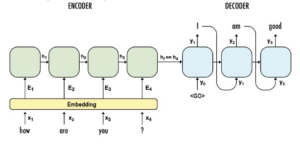
Figure 1: A sequence-to-sequence (S2S) architecture model[1].
The entire architecture learns the mapping from the input to the output in an end-to-end approach. In deep learning training, an end-to-end training paradigm specifies that the whole task, from taking in the input to generating the final output, is trained together. Figure 1 shows an example of how an S2S architecture works for a model that is learning to converse with the user. The input is “How are you?” and the desired output is “I am good.”
2.2 Sequence Tagging Models
As mentioned previously, the sequence tagging approach is trained to detect inconsistencies in shorter, localized text spans. These models differ from the S2S models as they do not generate the complete target sentence. Rather, they go over each token in the input and generate labels such as “KEEP,” “EDIT,” and “DELETE” for them. As a result, they perform GED on each word or token to perform the overall GEC.
Some examples of this architecture can be observed in the GECToR [OACS20] and PIE tagged-editing GEC models [ASG+19]. These models utilize the specific editing labels for each word in the source sentence to edit them.
2.3 Precision and Recall Trade-off
It has been observed in different GEC systems that there is a trade off between precision and recall. Precision and recall are classification evaluation metrics that can be used to ascertain how well a model is performing its classification task. Precision is a metric to observe how precise and accurate the corrections are. Recall is a measure of how many corrections the system is making. This can be summarized simply as follows: How many corrections did the model make, and how accurate were they?
We see that GEC systems tend to have higher precision scores in comparison to their recall scores. To improve the recall score, we typically only use sentences that require corrections for training. It has been observed that if we use correct sentences for training, the model tends to improve on its precision score but suffers on its recall metric score.
For a GEC system focusing on text improvement or text editing, a higher precision is often more useful than better recall. A system end user is happy to see changes that are actually correct without too many corrections that edit the original sentence unnecessarily.
3 Models
In this experiment, we trained a GED model to perform a preliminary pass over a set of sentences being evaluated for corrections. This allowed us to filter the incorrect sentences and reduce the sentences that the GEC system needed to evaluate. If the GED system marked a sentence as “correct,” we could assume that the target or prediction was the same as the input-source sentence. Using this filtering method, we only pass the sentences marked “incorrect” to the GEC system.
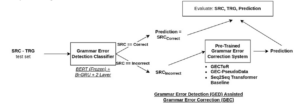
Figure 2: GED-assisted GEC model pipeline.
Figure 2 describes the overall process of our approach, which was modeled after a two submodule ensemble approach. The first module was the GED classifier we trained. This model takes the set of GEC test sentences and labels them as “correct” or “incorrect.” If the model predicts the label as “correct,” those sentences are not processed further. The Prediction is the same as Source for these sentences. The set of sentences labelled “incorrect” is sent to the GEC submodule that generates the Prediction for those sentences.
The GEC sub-module is one of the GEC systems that we evaluated in this study. In the end, the set of Predictions for the test set is aggregated and the system performance is evaluated.
We performed our evaluation on models that we trained as well as on two state-of-the-art GEC systems.
3.1 Grammar Error Detection
We trained models for GED based on the BERT [DCLT18] and GPT2 [RWC1] pre-trained language models. The BERT and GPT2 models are examples of massive pre-trained architecture that have shown exceptional performance in a variety of NLP tasks [KRS21]. BERT is an encoder-only architecture that generates a representation for the input sentence, whereas GPT2 is a decoder-only model used to generate conditional text as well as a representation for it.
We used the sentence representation generated by the BERT [DCLT18] and GPT2 [RWC1] models and sent it as input to an RNN-GRU model. The pre-trained language model (PLM) can be thought of as an encoder block and the GRU as a simple decoder block. We used a bi-directional two-layer GRU model to generate the “correct” or “incorrect” labels for the input sentence. Figure 3 shows the architecture for our GED model.
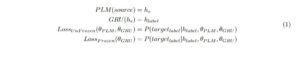
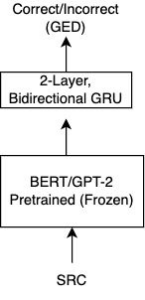
Figure 3: Grammar error detection model for the input source sentence (SRC).
Equation 1 describes our GED model’s architecture and training objective (loss). The source sentence is passed to the pre-trained language model (PLM), BERT or GPT2, which generates the sentence representation, hs. The hs is passed as input to the GRU block, which generates the representation for the final “correct” or “incorrect” label.
We trained variations of the model, Frozen and UnFrozen, as can be observed in the two different losses. In the Frozen model, the pre-trained LM is not updated while training the GED system. In this way, only the GRU model is trained and the PLM provides the sentence representation embedding for the input. In the UnFrozen model, all the components are trained and updated.
3.2 Public Models
In this experiment, we evaluated two state-of-the-art public models. One model used sequence tagging architecture, while the other was based on the S2S text-generation approach.
3.2.1 GECToR – Sequence Edit Model
The GECToR model is a state-of-the-art architecture for GEC [OACS20]. It was trained using the BERT [DCLT18] model as a token classifier. Since it performs individual token/word classification, it is a sequence-tagging model. Apart from the main labels (KEEP, DELETE, and EDIT), careful and fine-grained transformation labels were developed for use in case-specific transformations. These edits were called g-transformations, and they focus on attributes like CASE, MERGE, and TENSE. Using this approach, the model “broke down” the editing labels into 5000 unique edits.
The model was trained in multiple stages and on different types of synthetic and public training data.
3.2.2 GEC-PseudoData Model
The second public model we evaluated was released in the paper “An Empirical Study of Incorporating Pseudo Data into Grammatical Error Correction” by Kiyono et al. [KSM+19]. This model utilized the basic S2S architecture proposed by Vaswani et al. [VSP+17] but focused on training the model with a large set of data. This dataset was generated synthetically by performing various sampling, noising, and back-translation approaches. Using this synthetic data generation approach, the system was trained on 70 million pairs of sentences.
3.3 Our Models
For this experiment, we trained an S2S architecture model [VSP+17] and an end-to-end S2S architecture that contained a conditional GED component.
3.3.1 Sequence-to-Sequence Model
We trained an S2S model similar to the one proposed by Vaswani et al. [VSP+17] as a baseline for the GEC task. Figure 4 shows the training approach for our model. This architecture is similar to the one used in the GEC-PseudoData experiment [KSM+19], and we used the Transformer architecture for our model.

Figure 4: Baseline S2S GEC model.
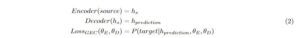
Equation 2 defines the training objective for the S2S baseline model. The encoder block takes the source sentence and generates a representation of it. The decoder then uses this representation to generate the prediction.
3.3.2 Shared Encoder Model with GED
Similar to the baseline S2S model (Figure 4), we designed a model with an additional GED classifier. Figure 5 shows the modified architecture of our approach.
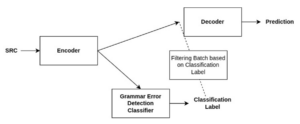
Figure 5: Shared encoder GEC model with a GED classifier.
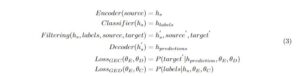
Equation 3 describes our system’s training objective. In this model, we send the source batch through the encoder to get the sentence representation for the batch, hs. This representation is sent to the GED classifier to predict the label for each batch sentence. The sentences deemed correct are filtered from the batch. Otherwise the filtering process passes on h‘s, source′, and target’ as the incorrect sentences. This information is sent to the decoder so that it can generate the predicted sentences.
We had individual losses to update the GEC and GED components, which were optimized simultaneously. In our approach, we trained the model to predict the “correct” or “incorrect” labels for a sentence and we trained the decoder to predict the target for “incorrect” sentences.
4 Experiments
In this section, we describe our experiment training setup, evaluation metrics, and results, as well as the data we used.
4.1 Data and Evaluation
- Synthetic Data
- Synthetic PIE Dataset [ASG+19]
- Public Training Data
- Evaluation Data
To evaluate our GED system, we used classification accuracy that can be obtained using the following:
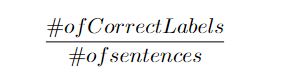
The GEC system was evaluated using the errant scorer metric [BFB17]. The errant scorer was introduced as an improvement over the M2 scorer [DN12], which is a widely used metric for GEC systems. The errant score utilizes the M2 structured text file in which the target and prediction sentences are aligned and the proper edits are listed with their starting and ending indices. The authors’ careful evaluation of the errant toolkit against actual human judgment showed that it performed better than the M2 scorer. It was able to account for the linguistic properties of the edits and the text, thus generating better evaluation scores. The errant score is represented in terms of precision and recall.
The GEC system often has to deal with a trade off between the precision and recall of the errant/M2 scores (section 2.3). For our experiments, we introduced a new evaluation metric based on the number of correct and incorrect edits that a GEC system makes. We defined this as the GEC system’s “usefulness.”
4.1.1 Usefulness Evaluation Metric
In our application of GEC text editing, we wanted to evaluate the effectiveness of the model for an end user or professional editor. To evaluate this “usefulness” criterion, we opted to use a simple metric that calculates the difference between the number of correct and incorrect edits a GEC system makes. We propose that a better GEC system will have a higher usefulness metric score, as this would mean that a GEC model corrects more errors than it introduces and is ultimately helpful to the end user. Intuitively, this usefulness score tells us the number of edits that the system has saved for users. By assigning a score of 1 for every correct edit and -1 for every incorrect edit and then summing the scores, the difference between the number of correct and incorrect edits indicates the system’s usefulness.
The errant and M2 scores defined for the GEC task make use of an M2 file generated for a pair of sentences: A and B. It lists the edits and the positions of those edits, which can turn sentence A into sentence B. To evaluate the performance of a GEC system, two M2 files are generated: one for the (Source-Target) sentence pair and one for the (Source-Prediction) sentence pair. The Source Sentences are evaluated, and the Target Sentences are the reference sentences for the Source Sentences that have the appropriate corrections. The Prediction Sentences are the predictions made by the GEC system for the Source Sentences. Table 1 presents an example of the M2 file generated for the source-target and source-prediction sentences. The M2 file contains the edits as well as information about them, such as their types and positions.

Table 1: M2 format example with edits generated between the (Source-Target) and (Source-Prediction) sentence pairs.
From the introduction paper for the GEC task and the M2 scorer by Dahlmeier et al. [DN12], we observed that initially the GEC task was evaluated by using the F1 score. However, for the CONLL-14 GEC task, the F0.5 score, in which the precision score has double the weight of the recall score, was used. In many GEC models there is a constant trade off between precision and recall (Section 2.3). It felt like an arbitrary decision (without any selection criteria) to make precision twice as important as recall because GEC models often have lower recall. We also argue that the M2 score might be better at evaluating the number of errors the model caught rather than ensuring that the input sentence was not destroyed. To overcome these issues, we propose a “usefulness” metric that focuses on the number and type of edits. The position and the actual edit information from the M2 file can be used to generate the score for this “usefulness” metric.

Table 2: Precision:Recall:M2 scores for predictions made by two different GEC models.
Table 2 shows the outputs and the M2 scores of two GEC models. We see that even though Prediction 1 may seem more appropriate, it is assigned an M2 score of 0.0. On the other hand, even though Prediction 2 introduces many inconsistencies into the source sentence, it gets a better M2 score since it matches a single edit in the target reference. With the “usefulness” score, we wish to take into account the number of correct and incorrect edits.
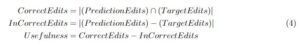 Equation 4 describes the Usefulness metric, proposed by us, based on the edits the M2 file provided. Prediction Edits refer to the edits generated by the (Source-Prediction) M2 file (Listing 2), and Target Edits refer to the edits generated by the (Source-Target) M2 file (Listing 1). For the example provided in Table 1, we can see that
Equation 4 describes the Usefulness metric, proposed by us, based on the edits the M2 file provided. Prediction Edits refer to the edits generated by the (Source-Prediction) M2 file (Listing 2), and Target Edits refer to the edits generated by the (Source-Target) M2 file (Listing 1). For the example provided in Table 1, we can see that
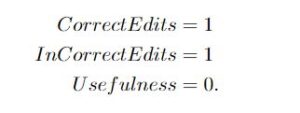

Table 3: Correct:Incorrect:Usefulness scores for predictions made by two different GEC models.
Table 3 shows the M2 files and the “usefulness” scores generated for the two predictions. Comparing the usefulness and M2 scores (Table 3 with Table 2), we can see that usefulness score may be better at comparing the types and number of edits. We compared the performance of our GEC models, before and after the introduction of the GED classifier filtering, utilizing the usefulness metric. We propose that the usefulness score based on the edits might provide a better evaluation than the trade off between the precision and recall scores.
4.2 Experiment Setup
The public GEC models (GECToR and GEC-PseudoData) were downloaded from their public GitHub repositories[2][3] and used as is.
The other models were trained and fine-tuned in stages.

Table 4: Training datasets used during different stages.
We initially trained both the GED and GEC models on the PIE-Synthetic data set. This is called the stage 1 or the pre-training phase. Then, we fine-tuned the models on the public data sets mentioned in Table 4.
4.3 Results
Table 5 describes the performance obtained by the different GED models described in Section 3.1 and Figure 3 after their first stage of training. The BERT- and GPT2-based models were evaluated on the PIE-Synthetic test dataset. Considering that the BERT (Frozen) + GRU model performed the best, we selected that model for further training on the public data sets.

Table 5: The performance of different GED models on the PIE-Synthetic test set after Stage 1 training.

Table 6: Classification accuracy of (BERT (Frozen) + GRU) – GED-classifier after fine-tuning on the public evaluation dataset.
Table 6 describes the performance of our GED classifier on the different public data sets. We evaluated the classifier by assessing how well it could distinguish between “correct” and “incorrect” sentences in the public data test set.
Tables 7 and 8 provide the errant score results obtained after using the GED model to filter the three models given in Figure 2. The score is provided using a Precision:Recall metric. As discussed before, GEC often requires a trade off between precision and recall (Section 2.3). We feel that precision may be more important than recall for GEC, since viewers tend to view incorrect edits negatively, especially when they must fix them. As a result, we focused on the precision performance of the models and have provided a recall score for completeness.
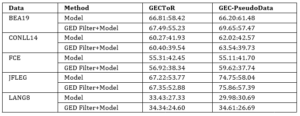
Table 7: Errant score (Precision:Recall) of the public state-of-the-art GEC systems after filtering the results with the GED classifier.
Table 7 describes the performance of state-of-the-art public models, namely GECToR (tagged editing model) [OACS20] and GEC-PseudoData (S2S model) [KSM+19]. The method column distinguishes between each public model and the same with the GED-classifier filtering approach. The GED Filter+Model method results were obtained from the model being evaluated after we performed the GED filtering. We observed that the GED filtered model (Figure 2) provides an improvement in the model’s precision score.
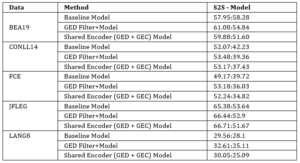
Table 8: Errant score (Precision:Recall) of our GEC systems after filtering the results with the GED classifier.
The results obtained by the models we trained (described in section 3.3) are provided in Table 8. Baseline S2S GEC model, the sequence-to-sequence model we trained (Figure 4), is similar in architecture to the GEC-PseudoData public model. However, we trained our model on the publicly available GEC data mentioned in section 4.1. Our GED Filter + Baseline Model (Figure 2) provided insights similar to those that the GEC-PseudoData model provided, in which an improvement in the precision score was obtained after filtering with the GED model. However, we observed decreased performance compared to the GEC-PseudoData model, which can be explained by the fact that we trained our model on a significantly smaller publicly available data set. The Shared Encoder (GED + GEC) Model method corresponds to the shared encoder model mentioned in Figure 5, which is trained to perform GED and GEC jointly. In contrast, the GED Filter + Baseline Model method uses a hybrid approach with separate GED and GEC components.
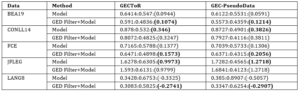
Table 9: Average Correct Edits:Incorrect Edits:(Usefulness) scores for the public state-of-the-art models filtered by the GED model.
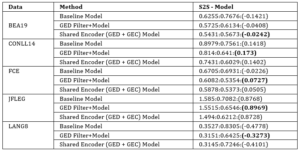
Table 10: The average Correct Edits:Incorrect Edits (Usefulness) scores for the models trained by us.
For the same models and setup described above in Tables 7 and 8, we present the “correct” and “incorrect” edits and the Usefulness score for the public state-of-the-art models in Table 9. Table 10 lists the Usefulness scores for the models we trained on the public data set.
4.4 Discussion of the Results
After training and evaluating the GED models, we found that the BERT [DCLT18] model (Frozen) performed better than all the other models. Hence, we selected this model for further fine-tuning and performed the evaluation using the GED filter method (Figure 2).
After comparing the results obtained from all the GEC models (Model method) and filtering the test set with the GED model (GED Filter + Model method), we observed that there was an improvement in the precision scores of the models. This follows the reasoning that when correct sentences are filtered, corrections are made only to the incorrect sentences. As a result, unnecessary corrections are avoided. On the other hand, because models may generate fewer corrections, they suffer from reduced recall scores. To better understand this score trade off (Section 2.3), we focused on the Usefulness score and found an improvement using the hybrid (GED Filter + Model) method.
We found that the addition of the GED submodule (Shared Encoder [GED + GEC] model [Figure 5]) inside the training pipeline resulted in a higher precision score compared to the baseline model. However, as seen with other models that were trained on an equal distribution of “correct” and “incorrect” sentences, we noted a recall score reduction. An explanation for this may be that our model’s encoder and decoder components tended to perform fewer and more obvious edits as they encountered sentences that did not require edits during training. The shared encoder for both GEC and GED components, along with the classification performance of the GED module, may also be responsible for the variation between precision and recall scores.
Considering our task of performing text editing on formal documents, having a high precision model is beneficial (i.e., it generates proper corrections efficiently). However, we do need to ensure an efficient recall score as we require models that cover and correct a vast variety of possible errors. Keeping this in mind, the GED-Filter + Model method that makes use of the separate GED and GEC components (hybrid model) may be helpful. Aside from reducing the inference time, it could provide better precision while preventing significant degradation to the recall score. We also saw an improvement in the Usefulness scores for all models we trained that utilize a hybrid filtering approach (except on the BEA19 data set, where the Shared Encoder Method performed better), which strengthens our hypothesis that using an additional GED classifier to filter the correct sentences and applying a GEC model only to the incorrect sentences can be helpful for the end user or editor.
5 Conclusions
We conducted this experiment to compare the performance of different GEC models with the addition of a hybrid component using a GED classifier. We also trained and tested different GED classifiers, choosing a BERT [DCLT18]-based classifier as our GED model.
Different state-of-the-art public GEC models were evaluated along with models we trained on publicly available GEC data. We observed that there were improvements in the precision scores for all models when the GED classifier was used to filter incorrect sentences.
We also observed that the hybrid evaluation setup with the external GED classifier (GED Filter+Baseline method) was a better architecture choice than the Shared Encoder method as it had better precision and recall scores. For GEC, we consider precision to be a more relevant estimate of evaluation because the end users of these models do not want unnecessary correction suggestions.
To overcome this trade off between the precision and recall scores, we propose an additional evaluation metric—the Usefulness score, based on the edits performed by a GEC system. Comparing the models on this Usefulness score demonstrated that there was an improvement in GEC systems that use the hybrid GED Filter + Model method, which showed us that GED filtering can be a simple and helpful approach for end users or editors.
For future work, we believe a careful study of the precision and recall trade off of these models is an important direction, as we need to carefully consider the difference in evaluating the GEC models with a classification score while the models generate text. Another interesting direction is to consider how these evaluations and the precision-recall trade off affect other sentence evaluation metrics, such as the generated sentence’s fluency and syntax structure.
References
[ASG+19] Abhijeet Awasthi, Sunita Sarawagi, Rasna Goyal, Sabyasachi Ghosh, and Vihari Piratla. Parallel iterative edit models for local sequence transduction. arXiv preprint arXiv:1910.02893, 2019.[BFB17] Christopher Bryant, Mariano Felice, and Edward Briscoe. Automatic annotation and evaluation of error types for grammatical error correction. Association for Computational Linguistics, 2017.
[CGCB14] Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Bengio. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555, 2014.
[DCLT18] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-
training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
[DN12] Daniel Dahlmeier and Hwee Tou Ng. Better evaluation for grammatical error correction. In Proceedings of the 2012 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 568–572, 2012.
[DNW13] Daniel Dahlmeier, Hwee Tou Ng, and Siew Mei Wu. Building a large annotated corpus of learner english: The nus corpus of learner English. In Proceedings of the eighth workshop on innovative use of NLP for building educational applications, pages 22–31, 2013.
[Gra14] Sylviane Granger. The computer learner corpus: A versatile new source of data for SLA research. In Learner English on computer, pages 3–18. Routledge, 2014.
[HS97] Sepp Hochreiter and Ju¨rgen Schmidhuber. Long short-term memory. Neural computation, 9(8): pages 1735–1780, 1997.
[KRS21] Katikapalli Subramanyam Kalyan, Ajit Rajasekharan, and Sivanesan Sangeetha. Ammus: A survey of transformer-based pretrained models in natural language processing. arXiv preprint arXiv:2108.05542, 2021.
[KSM+19] Shun Kiyono, Jun Suzuki, Masato Mita, Tomoya Mizumoto, and Kentaro Inui. An empirical study of incorporating pseudo data into grammatical error correction. arXiv preprint arXiv:1909.00502, 2019.
[NST17] Courtney Napoles, Keisuke Sakaguchi, and Joel Tetreault. Jfleg: A fluency corpus and benchmark for grammatical error correction. arXiv preprint arXiv:1702.04066, 2017.
[OACS20] Kostiantyn Omelianchuk, Vitaliy Atrasevych, Artem Chernodub, and Oleksandr Skurzhanskyi. Gector–grammatical error correction: Tag, not rewrite. arXiv preprint arXiv:2005.12592, 2020.
[RWC+] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.
[TKM12] Toshikazu Tajiri, Mamoru Komachi, and Yuji Matsumoto. Tense and aspect error correction for ESL learners using global context. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 198–202, 2012.
[VSP+17] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, L ukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
[YAG+18] Helen Yannakoudakis, Øistein E Andersen, Ardeshir Geranpayeh, Ted Briscoe, and Diane Nicholls. Developing an automated writing placement system for ESL learners. Applied Measurement in Education, 31(3): pages 251–267, 2018.
[YBM11] Helen Yannakoudakis, Ted Briscoe, and Ben Medlock. A new dataset and method for automatically grading ESOL texts. In Proceedings of the 49th annual meeting of the association for computational linguistics: human language technologies, pages 180–189, 2011.
[1] Modified diagram from https://towardsdatascience.com/sequence-to-sequence-model-introduction-andconcepts-44d9b41cd42d
[2] https://github.com/grammarly/gector
[3] https://github.com/butsugiri/gec-pseudodata