
Scribendi Inc. is using leading-edge artificial intelligence techniques to build tools that help professional editors work more productively. In this blog, we highlight our research for the benefit of data scientists and other technologists seeking similar results. This article addresses machine learning strategies and tools to score sentences based on their grammatical correctness.
Background
In an earlier article, we discussed whether Google’s popular Bidirectional Encoder Representations from Transformers (BERT) language-representational model could be used to help score the grammatical correctness of a sentence. Our research suggested that, while BERT’s bidirectional sentence encoder represents the leading edge for certain natural language processing (NLP) tasks, the bidirectional design appeared to produce infeasible, or at least suboptimal, results when scoring the likelihood that given words will appear sequentially in a sentence. This technique is fundamental to common grammar scoring strategies, so the value of BERT appeared to be in doubt.
Since that article’s publication, we have received feedback from our readership and have monitored progress by BERT researchers. Their recent work suggests that BERT can be used to score grammatical correctness but with caveats. This follow-up article explores how to modify BERT for grammar scoring and compares the results with those of another language model, Generative Pretrained Transformer 2 (GPT-2). This comparison showed GPT-2 to be more accurate.
BERT’s Purpose and Design
When first announced by researchers at Google AI Language, BERT advanced the state of the art by supporting certain NLP tasks, such as answering questions, natural language inference, and next-sentence prediction. BERT’s language model was shown to capture language context in greater depth than existing NLP approaches.
A language model is defined as a probability distribution over sequences of words. It is trained traditionally to predict the next word in a sequence given the prior text. However, BERT is not trained on this traditional objective; instead, it is based on “masked” language modeling objectives, predicting a word or a few words given their context to the left and right. Because BERT expects to receive context from both directions, it is not immediately obvious how this model can be applied like a traditional language model.
A common application of traditional language models is to evaluate the probability of a text sequence. In the case of grammar scoring, a model evaluates a sentence’s probable correctness by measuring how likely each word is to follow the prior word and aggregating those probabilities. If a sentence’s “perplexity score” (PPL) is Iow, then the sentence is more likely to occur commonly in grammatically correct texts and be correct itself. (Read more about perplexity and PPL in this post and in this Stack Exchange discussion.) Grammatical evaluation by traditional models proceeds sequentially from left to right within the sentence.
Jacob Devlin, a co-author of the original BERT white paper, responded to the developer community question, “How can we use a pre-trained [BERT] model to get the probability of one sentence?” He answered, “It can’t; you can only use it to get probabilities of a single missing word in a sentence (or a small number of missing words). This is one of the fundamental ideas [of BERT], that masked [language models] give you deep bidirectionality, but you no longer have a well-formed probability distribution over the sentence.” This response seemed to establish a serious obstacle to applying BERT for the needs described in this article.
Applying BERT to Grammar Scoring
For our team, the question of whether BERT could be applied in any fashion to the grammatical scoring of sentences remained. Through additional research and testing, we found that the answer is yes; it can.
A technical paper authored by a Facebook AI Research scholar and a New York University researcher showed that, while BERT cannot provide the exact likelihood of a sentence’s occurrence, it can derive a pseudo-likelihood. This can be achieved by modifying BERT’s masking strategy. Instead of masking (seeking to predict) several words at one time, the BERT model should be made to mask a single word at a time and then predict the probability of that word appearing next. The model repeats this process for each word in the sentence, moving from left to right (for languages that use this reading orientation, of course). Finally, the algorithm should aggregate the probability scores of each masked work to yield the sentence score, according to the PPL calculation described in the Stack Exchange discussion referenced above. This algorithm offers a feasible approach to the grammar scoring task at hand.
In our previous post on BERT, we noted that the out-of-the-box score assigned by BERT is not deterministic. However, it is possible to make it deterministic by changing the code slightly, as shown below:
Figure 1. Code for Masked Bert
import sys
import numpy as np
import torch
from transformers import BertTokenizer,BertForMaskedLM
# Load pre-trained model (weights)
with torch.no_grad():
model = BertForMaskedLM.from_pretrained('bert-large-cased')
model.eval()
# Load pre-trained model tokenizer (vocabulary)
tokenizer = BertTokenizer.from_pretrained('bert-large-cased')
def score(sentence):
tokenize_input = tokenizer.tokenize(sentence)
tokenize_input = ["[CLS]"]+tokenize_input+["[SEP]"]
tensor_input = torch.tensor([tokenizer.convert_tokens_to_ids(tokenize_input)])
with torch.no_grad():
loss=model(tensor_input, masked_lm_labels=tensor_input)[0]
return np.exp(loss.detach().numpy())
if __name__=='__main__':
for line in sys.stdin:
if line.strip() !='':
print(line.strip()+'\t'+ str(score(line.strip())))
else:
break
Figure 2. Code for GPT-2
import torch
import sys
import numpy as np
from transformers import GPT2Tokenizer, GPT2LMHeadModel
# Load pre-trained model (weights)
with torch.no_grad():
model = GPT2LMHeadModel.from_pretrained('gpt2')
model.eval()
# Load pre-trained model tokenizer (vocabulary)
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
def score(sentence):
tokenize_input = tokenizer.encode(sentence)
tensor_input = torch.tensor([tokenize_input])
loss=model(tensor_input, labels=tensor_input)[0]
return np.exp(loss.detach().numpy())
if __name__=='__main__':
for line in sys.stdin:
if line.strip() !='':
print(line.strip()+'\t'+ str(score(line.strip())))
else:
break
Comparing BERT to GPT-2
Given BERT’s inherent limitations in supporting grammatical scoring, it is valuable to consider other language models that are built specifically for this task. A particularly interesting model is GPT-2. This algorithm is natively designed to predict the next token/word in a sequence, taking into account the surrounding writing style. Our question was whether the “sequentially native” design of GPT-2 would outperform the powerful but natively bidirectional approach of BERT.
First, we note that other language models, such as roBERTa, could have been used as comparison points in this experiment. We chose GPT-2 because it is popular and dissimilar in design from BERT.
For the experiment, we calculated perplexity scores for 1,311 sentences from a dataset of grammatically proofed documents. Each sentence was evaluated by BERT and by GPT-2. A subset of the data comprised “source sentences,” which were written by people but known to be grammatically incorrect. A second subset comprised “target sentences,” which were revised versions of the source sentences corrected by professional editors.
Seven source sentences and target sentences are presented below along with the perplexity scores calculated by BERT and then by GPT-2 in the right-hand column. A better language model should obtain relatively high perplexity scores for the grammatically incorrect source sentences and lower scores for the corrected target sentences.
BERT Source Sentence Samples
| Sentence | PPL Score |
| Humans have many basic needs and one of them is to have an environment that can sustain their lives. | 9.5856 |
| Our current population is 6 billion people and it is still growing exponentially. | 340.999704 |
| This will, if not already, caused problems as there are very limited spaces for us. | 37.4359 |
| From large scale power generators to the basic cooking at our homes, fuel is essential for all of these to happen and work. | 9.3192 |
| In brief, innovators have to face many challenges when they want to develop the products. | 24.5170 |
| The solution can be obtain by using technology to achieve a better usage of space that we have and resolve the problems in lands that inhospitable such as desserts and swamps. | 2.7365 |
| As the number of people grows, the need of habitable environment is unquestionably essential. | 10.0915 |
BERT Target Sentence Samples
| Sentence | PPL Score |
| Humans have many basic needs, and one of them is to have an environment that can sustain their lives. | 6.53150021 |
| Our current population is 6 billion people, and it is still growing exponentially. | 15.3410 |
| This will, if not already, cause problems as there are very limited spaces for us. | 9.0914 |
| From large scale power generators to the basic cooking in our homes, fuel is essential for all of these to happen and work. | 8.8007 |
| In brief, innovators have to face many challenges when they want to develop products. | 23.2450 |
| The solution can be obtained by using technology to achieve a better usage of space that we have and resolve the problems in lands that are inhospitable, such as deserts and swamps. | 4.6150 |
| As the number of people grows, the need for a habitable environment is unquestionably essential. | 13.3012 |
GPT-2 Source Sentence Samples
| Sentence | PPL Score |
| Humans have many basic needs and one of them is to have an environment that can sustain their lives. | 34.35451 |
| Our current population is 6 billion people and it is still growing exponentially. | 64.644646 |
| This will, if not already, caused problems as there are very limited spaces for us. | 191.08264 |
| From large scale power generators to the basic cooking at our homes, fuel is essential for all of these to happen and work. | 252.02832 |
| In brief, innovators have to face many challenges when they want to develop the products. | 125.920944 |
| The solution can be obtained by using technology to achieve a better usage of space that we have and resolve the problems in lands that inhospitable such as desserts and swamps. | 162.65608 |
| As the number of people grows, the need of habitable environment is unquestionably essential. | 182.57089 |
GPT-2 Target Sentence Samples
| Sentence | PPL Score |
| Humans have many basic needs, and one of them is to have an environment that can sustain their lives. | 15.6561542 |
| Our current population is 6 billion people, and it is still growing exponentially. | 22.983944 |
| This will, if not already, cause problems as there are very limited spaces for us. | 52.92566 |
| From large scale power generators to the basic cooking in our homes, fuel is essential for all of these to happen and work. | 103.73776 |
| In brief, innovators have to face many challenges when they want to develop products. | 42.154648 |
| The solution can be obtained by using technology to achieve a better usage of space that we have and resolve the problems in lands that are inhospitable, such as deserts and swamps. | 46.907337 |
| As the number of people grows, the need for a habitable environment is unquestionably essential. | 39.73967 |
You may observe that, with BERT, the last two source sentences display lower perplexity scores (i.e., are considered more likely to be grammatically correct) than their corresponding target sentences. This is the opposite of the result we seek.
Figure 3. PPL Distribution for BERT and GPT-2

A similar frequency of incorrect outcomes was found on a statistically significant basis across the full test set. Both BERT and GPT-2 derived some incorrect conclusions, but they were more frequent with BERT. A clear picture emerges from the above PPL distribution of BERT versus GPT-2. The target PPL distribution should be lower for both models as the quality of the target sentences should be grammatically better than the source sentences. This is true for GPT-2, but for BERT, we can see the median source PPL is 6.18, whereas the median target PPL is only 6.21. BERT shows better distribution shifts for edge cases (e.g., at 1 percent, 10 percent, and 99 percent) for target PPL. However, in the middle, where the majority of cases occur, the BERT model’s results suggest that the source sentences were better than the target sentences. In contrast, with GPT-2, the target sentences have a consistently lower distribution than the source sentences.
Figure 4. PPL Cumulative Distribution for BERT

Figure 5. PPL Cumulative Distribution for GPT-2
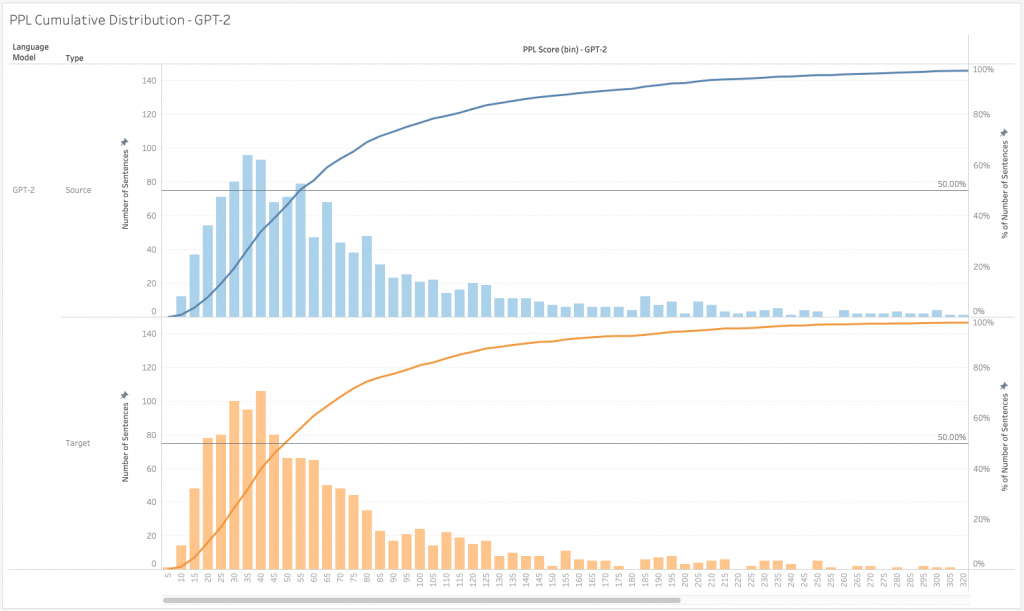
We can see similar results in the PPL cumulative distributions of BERT and GPT-2. The PPL cumulative distribution of source sentences is better than for the BERT target sentences, which is counter to our goals. In comparison, the PPL cumulative distribution for the GPT-2 target sentences is better than for the source sentences.
Based on these findings, we recommend GPT-2 over BERT to support the scoring of sentences’ grammatical correctness. The sequentially native approach of GPT-2 appears to be the driving factor in its superior performance.
Applications at Scribendi
We have used language models to develop our proprietary editing support tools, such as the Scribendi Accelerator. This is an AI-driven grammatical error correction (GEC) tool used by the company’s editors to improve the consistency and quality of their edited documents. The Scribendi Accelerator identifies errors in grammar, orthography, syntax, and punctuation before editors even touch their keyboards. This leaves editors with more time to focus on crucial tasks, such as clarifying an author’s meaning and strengthening their writing overall. See the “Our Tech” section of the Scribendi.ai website to request a demonstration.
We have also developed a tool that will allow users to calculate and compare the perplexity scores of different sentences. This also will shortly be made available as a free demo on our website.
The above tools are currently used by Scribendi, and their functionalities will be made generally available via APIs in the future. Please reach us at ai@scribendi.com to inquire about use.
References
Chromiak, Michał. “NLP: Explaining Neural Language Modeling.” Michał Chromiak’s Blog. Michał Chromiak’s Blog, November 30, 2017. https://mchromiak.github.io/articles/2017/Nov/30/Explaining-Neural-Language-Modeling/#.X3Y5AlkpBTY.
“Data.” CoNLL-2012 Shared Task. Modelling Multilingual Unrestricted Coreference in OntoNotes. http://conll.cemantix.org/2012/data.html.
Horev, Rani. “BERT Explained: State of the art language model for NLP.” Towards Data Science (blog). Medium, November 10, 2018. https://towardsdatascience.com/bert-explained-state-of-the-art-language-model-for-nlp-f8b21a9b6270.
Islam, Asadul. “Can We Use BERT as a Language Model to Assign a Score to a Sentence?” Scribendi AI (blog). Scribendi Inc., January 9, 2019. https://www.scribendi.ai/can-we-use-bert-as-a-language-model-to-assign-score-of-a-sentence/.
Khan, Sulieman. “BERT, RoBERTa, DistilBERT, XLNet—which one to use?” Towards Data Science. Medium, September 4, 2019. https://towardsdatascience.com/bert-roberta-distilbert-xlnet-which-one-to-use-3d5ab82ba5f8.
Learner. “What is perplexity?” Stack Exchange. Updated May 14, 2019, 18:07. https://stats.stackexchange.com/questions/10302/what-is-perplexity.
Radford, Alec, Wu, Jeffrey, Child, Rewon, Luan, David, Amodei, Dario and Sutskever, Ilya. “Language Models are Unsupervised Multitask Learners.” OpenAI. Updated 2019. https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf.
RoBERTa: An optimized method for pretraining self-supervised NLP systems.” Facebook AI (blog). Facebook AI, July 29, 2019. https://ai.facebook.com/blog/roberta-an-optimized-method-for-pretraining-self-supervised-nlp-systems/.
“Probability Distribution.” Wikimedia Foundation, last modified October 8, 2020, 13:10. https://en.wikipedia.org/wiki/Probability_distribution.
Schumacher, Aaron. “Perplexity: What it is, and what yours is.” Plan Space (blog). Plan Space from Outer Nine, September 23, 2013. https://planspace.org/2013/09/23/perplexity-what-it-is-and-what-yours-is/.
Wang, Alex, and Cho, Kyunghyun. “BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model.” Arxiv preprint, Cornell University, Ithaca, New York, April 2019. https://arxiv.org/abs/1902.04094v2.
Wangwang110. “Can the pre-trained model be used as a language model?” Github. Updated May 31, 2019. https://github.com/google-research/bert/issues/35.